GPT-SoVITS:强大的少样本语音克隆与 TTS 工具
GPT-SoVITS 是一个先进的少样本语音克隆和文本转语音(TTS)工具,只需 1 分钟的参考音频即可实现高质量语音克隆。该项目由 RVC-Boss 团队开发,结合 GPT 语义建模和扩散声学建模技术,在开源社区中获得广泛关注。其核心优势在于极低的训练数据需求、跨语言语音生成能力以及用户友好的 WebUI 界面,使得专业级语音合成技术触手可及。
核心功能
GPT-SoVITS 的核心竞争力体现在其革命性的少样本学习能力上。传统语音克隆系统通常需要数小时的音频数据,而 GPT-SoVITS 仅需 1 分钟参考音频即可克隆声音,这一突破性特性源于其创新的两阶段生成架构。
项目的关键功能包括:
- 零样本和少样本 TTS:无需额外训练即可生成新语音
- 跨语言语音生成:可以用中文训练数据生成英文、日文等语音
- 高质量音频输出:保持自然韵律和情感表达
- 完整的训练推理流程:集成数据预处理、ASR 对齐、模型训练和推理
独特之处在于其混合架构设计。GPT-SoVITS 将内容生成与音色特征分离,通过 GPT 模型处理语义理解和韵律预测,再由 SoVITS(基于 VITS 的改进版本)生成具体声学特征。这种设计不仅提升了音质,还实现了更好的可控性和跨语言能力。支持中文、英文、日文等多种语言,且能在不同语言间转换音色。
安装部署方法
系统要求
软件环境
- Windows、Linux 或 macOS 操作系统
- Python 3.9 或 3.10(推荐 3.10)
- pip、conda 或 uv 包管理器
- FFmpeg
硬件配置
- Nvidia GPU
使用 uv 的手动安装流程
uv 包管理器提供了比传统 pip 更快的安装体验,是个人推荐的安装方式之一。
完整安装步骤如下:
# 1. 克隆仓库
git clone https://github.com/RVC-Boss/GPT-SoVITS.git
cd GPT-SoVITS
# 2. 使用 uv 创建虚拟环境
uv venv --python 3.10
# 3. 激活虚拟环境
# Windows: .venv\Scripts\activate
# Linux/Mac: source .venv/bin/activate
# 4. 安装依赖(注意顺序和参数)
uv pip install -r extra-req.txt --no-deps
uv pip install -r requirements.txtDocker 安装方式
前置准备
- 需要安装 Docker 和 NVIDIA Container Toolkit(用于 GPU 支持)
- 确保 NVIDIA 驱动正常工作
Docker 方式提供了开箱即用的预配置环境,适合希望快速部署的用户。
部署
使用官方的 docker compose
WebUI 使用指南
启动 WebUI
安装完成后,根据安装方式选择对应的启动命令:
# 标准 Python 环境
python webui.py
# 使用 uv 环境
uv run python webui.py
# Windows 批处理文件
go-webui.bat启动后访问 http://localhost:9874/ 即可看到 WebUI 界面。
WebUI 包含三个主要标签页:
- 0-前置数据集获取工具:数据准备
- 1-GPT-SoVITS-TTS:模型训练和推理
- 2-GPT-SoVITS-变声:实时变声(开发中)
0-前置数据集获取工具

该工具组提供完整的数据预处理流程,包含四个步骤:
0a-UVR5 人声伴奏分离
从音频中分离人声和背景音,确保训练数据纯净。适用于处理包含背景音乐的视频或音频素材。
0b-语音切分
将长音频自动切分为适合训练的短片段(通常 2-10 秒)。
关键参数:
- threshold(音量阈值):默认 -34 dB,控制静音检测灵敏度
- min_length:最短片段长度,默认 4000 毫秒
- max_sil_kept:保留的静音长度,默认 500 毫秒
根据音频质量调整参数,噪音较大时可适当提高阈值。
0c-语音识别
使用 ASR 模型自动生成文本标注。输出格式为 .list 文件,每行包含音频路径和对应文本。
模型选择建议:
- 中文:达摩 ASR(中文)
- 英文/日文:选择对应语言的 ASR 模型
- 模型尺寸:large 精度高但慢,small 速度快但可能不够准确
0d-语音文本校对
提供可视化界面用于人工校对 ASR 识别结果。
校对重点:
- 修正专业术语、人名、地名
- 调整标点符号以符合韵律
- 删除质量不佳的音频样本
- 保持标注风格一致
数据质量直接影响训练效果,建议仔细校对每条标注。
1-GPT-SoVITS-TTS
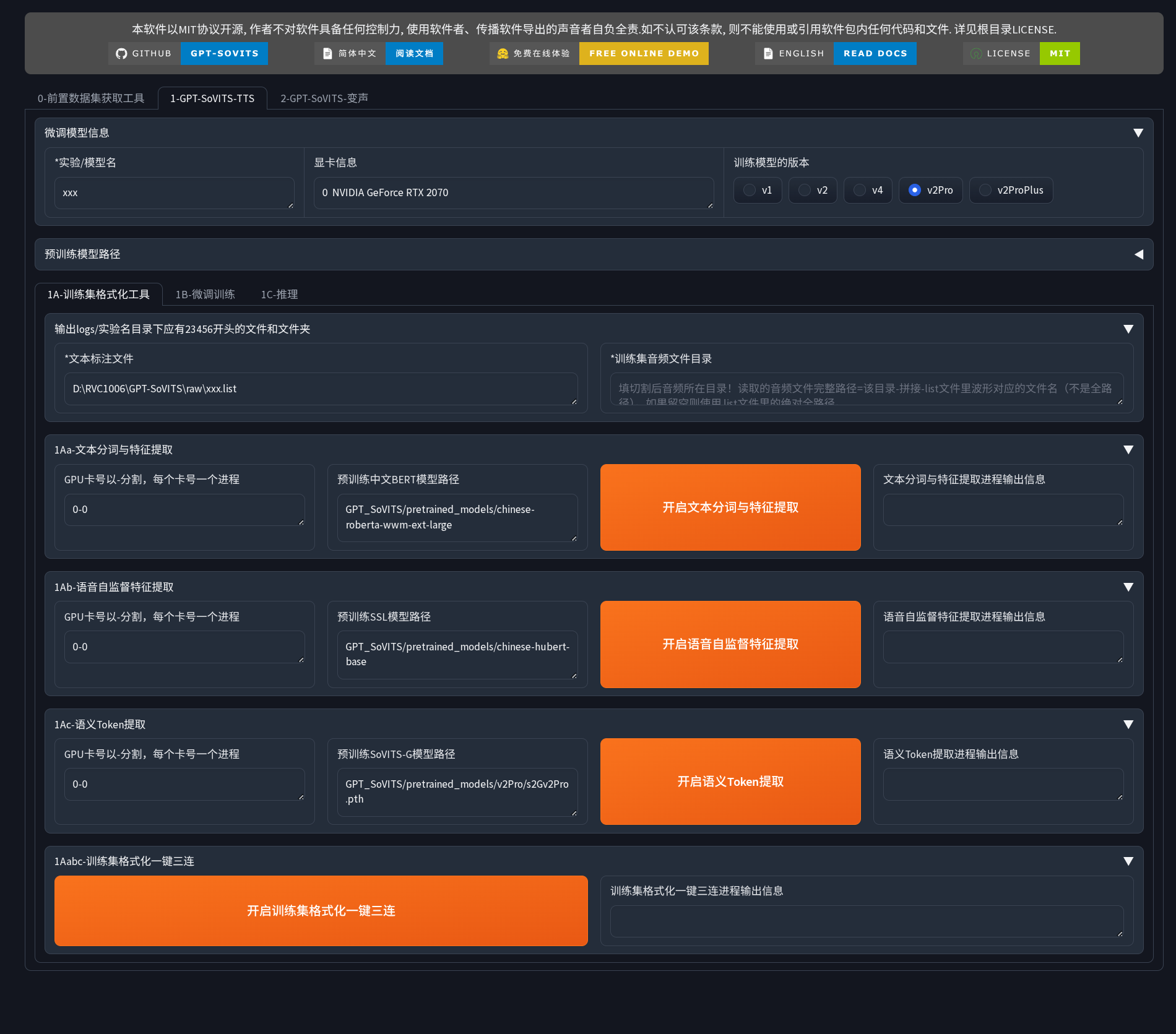
核心训练和推理界面,包含三个子标签页。
顶部配置
- 实验/模型名:为训练实验设置唯一标识名称
- 训练模型版本:推荐选择 v2Pro(兼容性和稳定性最佳)
1A-训练集格式化工具
将预处理好的数据转换为模型训练格式,包含三个步骤:
1Aa-文本分词与特征提取
使用 BERT 模型提取文本语义特征。在右侧文本框中可以查看和编辑训练样本列表,建议删除质量不佳的样本。
1Ab-语音自监督特征提取
从音频中提取深层声学特征(音色、韵律、音高等)。该步骤计算量大,处理时间取决于音频总时长和 GPU 性能。
1Ac-语义 Token 提取
使用 SoVITS 预训练模型生成语义令牌。注意确保预训练模型版本与顶部选择的训练版本一致。
一键三连
对于小数据集(5-10 分钟音频),可以使用"一键三连"按钮自动完成上述三个步骤。
1B-微调训练
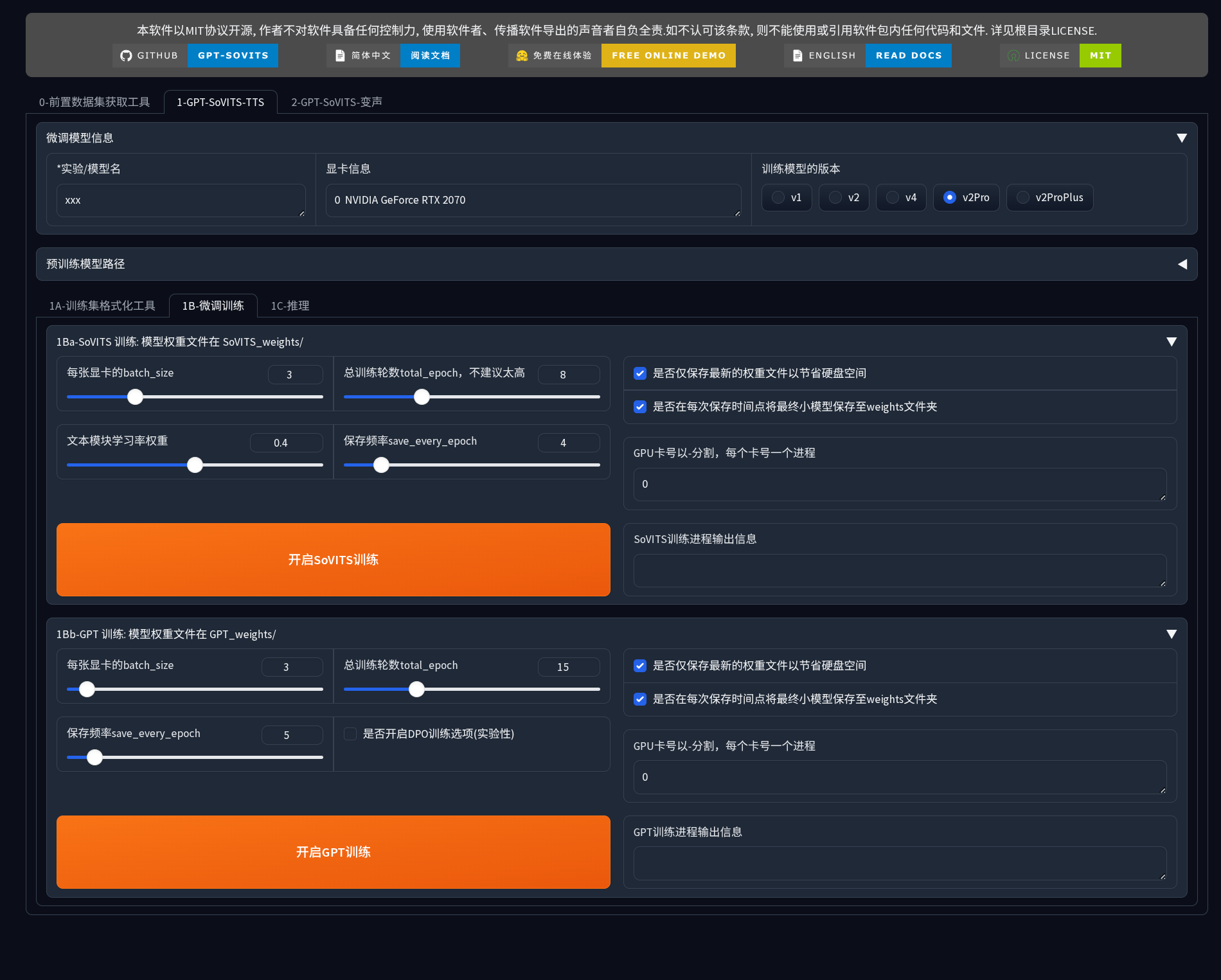
1Ba-SoVITS 训练
训练声学模型,学习目标音色特征。
核心参数:
- batch_size(批次大小):根据 GPU 显存调整
- total_epoch(总轮数):默认 8,范围 6-15
- save_every_epoch:默认 4,建议小数据集设为 2-3
存储选项:
- 首次训练建议不勾选"仅保存最新权重",以便对比不同阶段效果
- 勾选"保存小模型至 weights 文件夹"便于快速测试
训练时间参考:
- 3 分钟音频 + RTX 2070:约 20-40 分钟
- 5 分钟音频 + RTX 3090:约 15-30 分钟
1Bb-GPT 训练
训练语义模型,学习文本到语音的映射和韵律模式。
参数设置:
- total_epoch:默认 15(比 SoVITS 需要更多轮次)
- 小数据集:12-18 轮
- 中等数据集:10-15 轮
- batch_size:GPT 显存需求较高,显存不足时优先减小此参数
- DPO 训练模式:实验性功能,首次训练建议不开启
训练顺序:
- 先完成 SoVITS 训练
- 测试 SoVITS 效果,确保音色质量满意
- 再进行 GPT 训练
- 使用两个模型联合测试
1C-推理

语音合成界面,支持零样本和微调模型两种模式。
模型选择
零样本推理:两个下拉框都选择"不训练直接推理"的底模
微调模型推理:选择训练好的自定义模型(训练完成后点击"刷新模型路径"按钮更新列表)
推理 WebUI
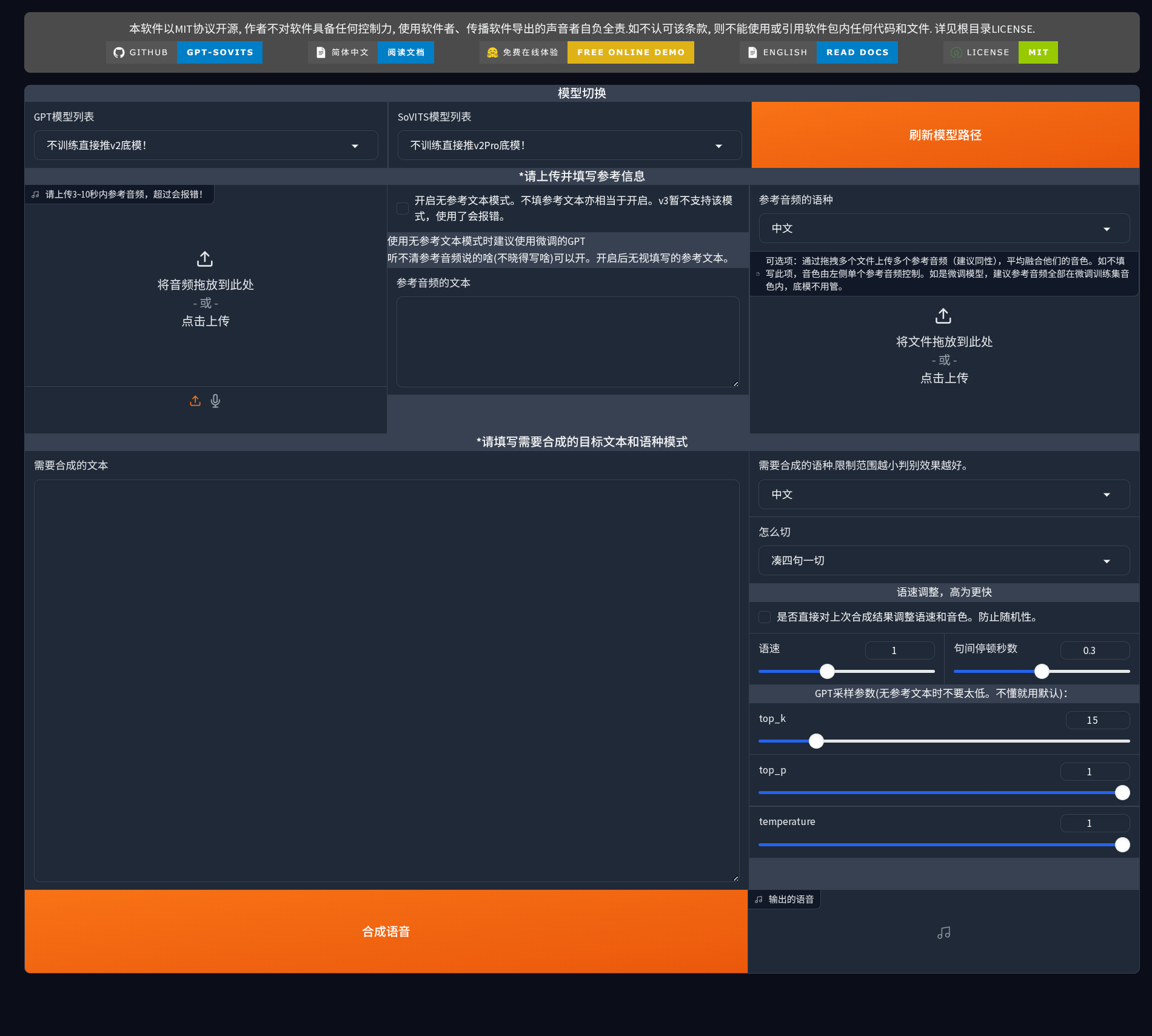
点击"关闭 TTS 推理 WebUI"按钮启动独立推理界面(通常地址为 http://localhost:9872/)。
左侧:参考音频和文本
- 参考音频:上传 3-10 秒清晰的目标音色音频
- 支持拖放、点击上传或直接录音
- 音频质量直接影响克隆效果
- 合成文本:输入要转换为语音的文本
- 注意标点符号(影响韵律和停顿)
- 长文本会自动分段处理
右侧:合成参数
- 语种设置:
- 参考音频语种:设置参考音频的语言
- 合成语种:设置输出语音的语言
- 支持跨语言克隆(如用中文音色生成英文语音)
- 切分方式(怎么切):
- 默认"凑四句一切"适合大多数场景
- 短文本可选"不切"
- 长文本建议按标点切分
- 语速调整:默认 1.0,范围 1.0-1.5
- 保持默认最自然
- 不建议超过 1.3
- 句间停顿:默认 0.3 秒
- 正常对话:0.2-0.4 秒
- 朗读风格:0.4-0.6 秒
GPT 采样参数(高级):
- top_k(默认 15):控制采样保守性
- 较低(5-10):更稳定一致
- 较高(20-50):更自然多样
- top_p(默认 1):核采样阈值,建议保持默认或 0.8-0.95
- temperature(默认 1):控制随机性
- 0.6-0.9:更稳定
- 1.1-1.3:更有变化
- 1.0 最平衡
配置完成后点击"合成语音"按钮,生成的音频会显示在界面底部,可直接播放和下载。
完整使用流程
快速体验(零样本)
- 启动 WebUI
- 进入"1C-推理"标签页
- 选择默认底模
- 上传 3-10 秒参考音频
- 输入合成文本
- 点击"合成语音"
微调训练(高质量)
第一阶段:数据准备
- 准备 3-10 分钟目标音色的高质量音频
- 使用"0a-人声伴奏分离"清理音频(如有背景音)
- 使用"0b-语音切分"切分音频
- 使用"0c-语音识别"生成文本标注
- 使用"0d-校对标注"人工修正错误
第二阶段:数据格式化
在"1A-训练集格式化工具"中:
- 执行"1Aa-文本分词与特征提取"
- 执行"1Ab-语音自监督特征提取"
- 执行"1Ac-语义 Token 提取"
或直接使用"一键三连"
第三阶段:模型训练
在"1B-微调训练"中:
- 配置 SoVITS 训练参数,点击"开启 SoVITS 训练"
- 等待训练完成(监控损失值变化)
- 配置 GPT 训练参数,点击"开启 GPT 训练"
- 等待训练完成
第四阶段:推理测试
- 进入"1C-推理"
- 刷新并选择训练好的模型
- 上传参考音频(微调后可以更短)
- 输入测试文本
- 调整参数并生成语音
- 评估效果,必要时调整参数重新生成
效果优化建议
音色不准确:
- 增加训练数据量(5-10 分钟)
- 确保训练数据纯净且音色一致
- 调整 SoVITS 训练轮数
韵律不自然:
- 检查文本标注的标点符号准确性
- 尝试不同的切分方式
- 调整 GPT 训练轮数
音质不清晰:
- 提升原始音频质量
- 检查切分参数(避免片段过短)
- 降低合成时的语速
实际应用场景
内容创作:
- 有声书和播客制作
- 视频配音和解说
- 游戏角色语音
- 多语言内容本地化
辅助技术:
- 个性化语音助手
- 语言学习工具
- 无障碍辅助
企业应用:
- 虚拟客服系统
- 企业培训材料
- 品牌音色统一
总结
GPT-SoVITS 将专业级语音克隆技术带给更广泛的用户群体,其创新的两阶段架构实现了高质量与低数据需求的平衡。
上手路径:
- 快速测试:Docker + 零样本推理
- 专业制作:手动安装 + 微调训练
项目持续更新中,访问 GitHub 仓库 获取最新文档和预训练模型。