GPT-SoVITS: Powerful Few-Shot Voice Cloning and TTS Tool
GPT-SoVITS is an advanced few-shot voice cloning and text-to-speech (TTS) tool that achieves high-quality voice cloning with just 1 minute of reference audio. Developed by the RVC-Boss team, this project combines GPT semantic modeling and diffusion acoustic modeling techniques, gaining widespread attention in the open-source community. Its core strengths lie in extremely low training data requirements, cross-lingual voice generation capabilities, and a user-friendly WebUI interface, making professional-grade speech synthesis technology accessible.
Core Features
GPT-SoVITS’s core competitiveness is embodied in its revolutionary few-shot learning capability. Traditional voice cloning systems typically require hours of audio data, whereas GPT-SoVITS can clone a voice with just 1 minute of reference audio. This breakthrough feature stems from its innovative two-stage generation architecture.
Key features of the project include:
- Zero-shot and few-shot TTS: Generate new voices without additional training
- Cross-lingual voice generation: Generate English, Japanese, and other languages using Chinese training data
- High-quality audio output: Maintains natural prosody and emotional expression
- Complete training and inference pipeline: Integrates data preprocessing, ASR alignment, model training, and inference
What makes it unique is its hybrid architecture design. GPT-SoVITS separates content generation from timbre features, using a GPT model for semantic understanding and prosody prediction, and then SoVITS (an improved version based on VITS) to generate specific acoustic features. This design not only enhances sound quality but also achieves better controllability and cross-lingual capabilities. It supports multiple languages including Chinese, English, and Japanese, and can convert timbres between different languages.
Installation and Deployment Methods
System Requirements
Software Environment
- Windows, Linux, or macOS operating system
- Python 3.9 or 3.10 (3.10 recommended)
- pip, conda, or uv package manager
- FFmpeg
Hardware Configuration
- Nvidia GPU
Manual Installation Process using uv
The uv package manager offers a faster installation experience than traditional pip, making it one of the recommended installation methods.
Complete installation steps are as follows:
# 1. Clone the repository
git clone https://github.com/RVC-Boss/GPT-SoVITS.git
cd GPT-SoVITS
# 2. Create a virtual environment using uv
uv venv --python 3.10
# 3. Activate the virtual environment
# Windows: .venv\Scripts\activate
# Linux/Mac: source .venv/bin/activate
# 4. Install dependencies (note order and parameters)
uv pip install -r extra-req.txt --no-deps
uv pip install -r requirements.txtDocker Installation Method
Prerequisites
- Docker and NVIDIA Container Toolkit (for GPU support) must be installed
- Ensure NVIDIA drivers are working correctly
The Docker method provides a ready-to-use, pre-configured environment, suitable for users who want to deploy quickly.
Deployment
Use the official docker compose
WebUI Usage Guide
Launching the WebUI
After installation, choose the corresponding launch command based on your installation method:
# Standard Python environment
python webui.py
# Using uv environment
uv run python webui.py
# Windows batch file
go-webui.batAfter launching, access http://localhost:9874/ to see the WebUI interface.
The WebUI includes three main tabs:
- 0-Preprocessing Dataset Acquisition Tool: Data preparation
- 1-GPT-SoVITS-TTS: Model training and inference
- 2-GPT-SoVITS-Voice Changer: Real-time voice changing (under development)
0-Preprocessing Dataset Acquisition Tool

This tool group provides a complete data preprocessing pipeline, including four steps:
0a-UVR5 Vocal Separation
Separates vocals from background music in audio, ensuring clean training data. Suitable for processing videos or audio materials containing background music.
0b-Audio Splitting
Automatically splits long audio into short segments suitable for training (typically 2-10 seconds).
Key Parameters:
- threshold (volume threshold): Default -34 dB, controls silence detection sensitivity
- min_length: Minimum segment length, default 4000 ms
- max_sil_kept: Length of silence to keep, default 500 ms
Adjust parameters according to audio quality; if noise is high, the threshold can be increased appropriately.
0c-Speech Recognition
Automatically generates text annotations using an ASR model. Output format is a .list file, with each line containing the audio path and corresponding text.
Model Selection Suggestions:
- Chinese: Damu ASR (Chinese)
- English/Japanese: Select the ASR model for the corresponding language
- Model size: Large for higher accuracy but slower speed, small for faster speed but potentially less accurate
0d-Speech Text Proofreading
Provides a visual interface for manual proofreading of ASR recognition results.
Proofreading Focus:
- Correcting specialized terms, names of people, and places
- Adjusting punctuation to match prosody
- Deleting low-quality audio samples
- Maintaining consistent annotation style
Data quality directly impacts training results, so careful proofreading of each annotation is recommended.
1-GPT-SoVITS-TTS
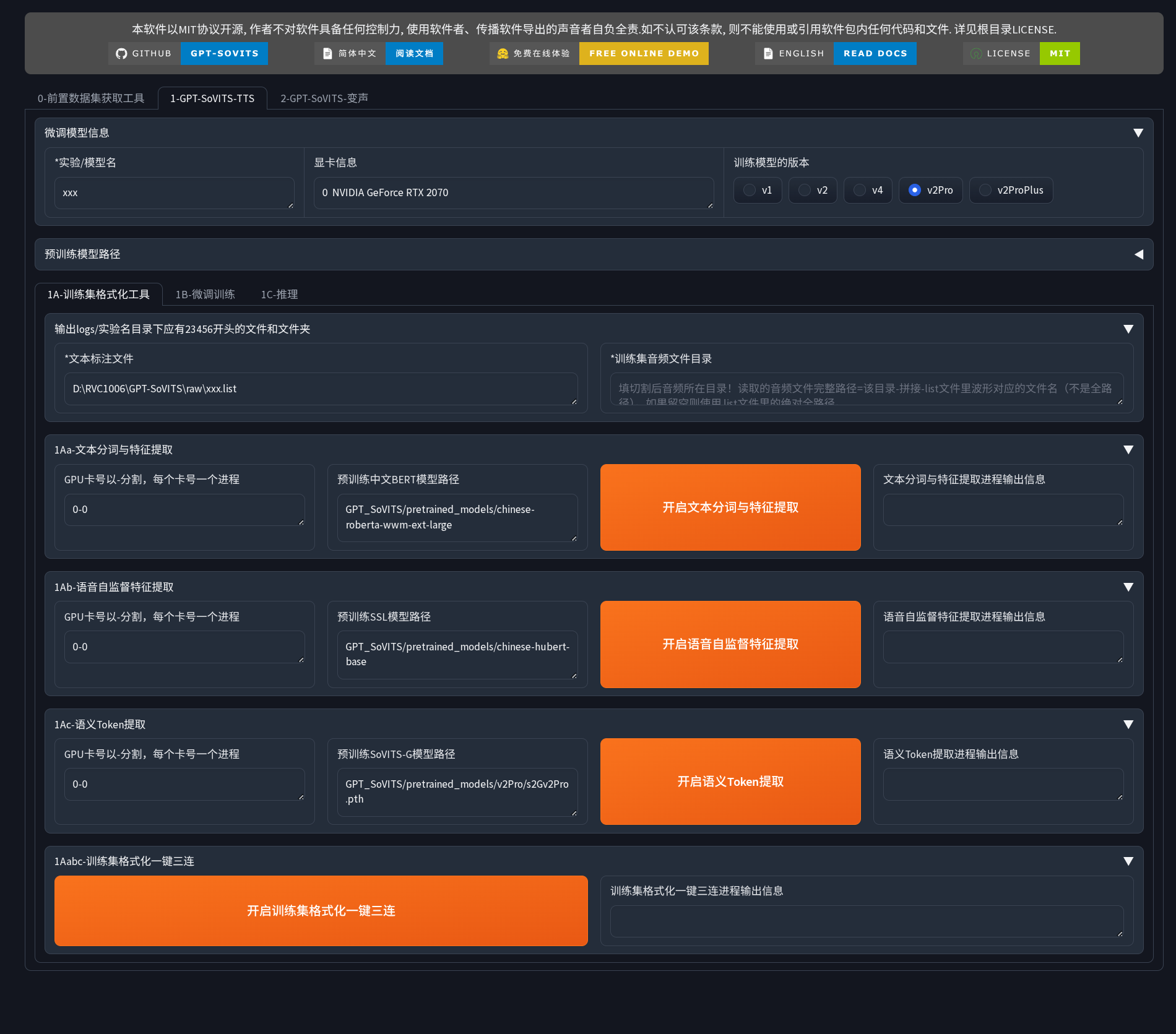
Core training and inference interface, containing three sub-tabs.
Top Configuration
- Experiment/Model Name: Set a unique identifier name for the training experiment
- Training Model Version: Recommended to choose v2Pro (best compatibility and stability)
1A-Training Set Formatting Tool
Converts preprocessed data into model training format, including three steps:
1Aa-Text Tokenization and Feature Extraction
Uses the BERT model to extract text semantic features. The right text box allows viewing and editing the training sample list; it is recommended to delete low-quality samples.
1Ab-Audio Self-Supervised Feature Extraction
Extracts deep acoustic features (timbre, prosody, pitch, etc.) from audio. This step is computationally intensive, and processing time depends on the total audio duration and GPU performance.
1Ac-Semantic Token Extraction
Generates semantic tokens using a SoVITS pre-trained model. Ensure that the pre-trained model version matches the training version selected at the top.
One-Click Triple Action
For small datasets (5-10 minutes of audio), the “One-Click Triple Action” button can be used to automatically complete the above three steps.
1B-Fine-tuning Training
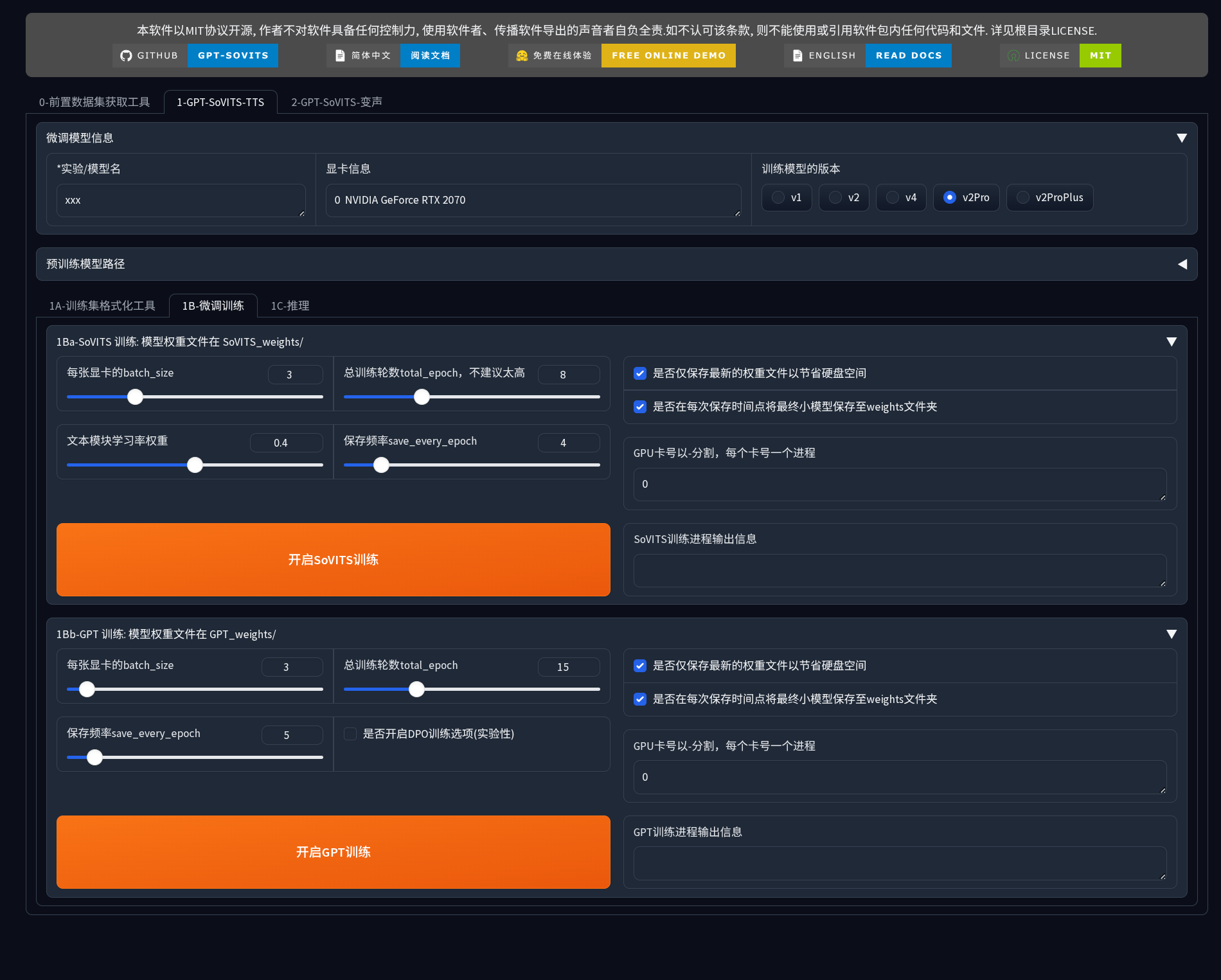
1Ba-SoVITS Training
Trains the acoustic model, learning target timbre features.
Core Parameters:
- batch_size: Adjust according to GPU VRAM
- total_epoch: Default 8, range 6-15
- save_every_epoch: Default 4, recommended to set to 2-3 for small datasets
Storage Options:
- For first training, it is recommended not to check “Only save latest weights” to compare effects at different stages
- Check “Save small model to weights folder” for quick testing
Training Time Reference:
- 3 minutes audio + RTX 2070: approximately 20-40 minutes
- 5 minutes audio + RTX 3090: approximately 15-30 minutes
1Bb-GPT Training
Trains the semantic model, learning text-to-speech mapping and prosody patterns.
Parameter Settings:
- total_epoch: Default 15 (requires more epochs than SoVITS)
- Small dataset: 12-18 epochs
- Medium dataset: 10-15 epochs
- batch_size: GPT has higher VRAM requirements; if VRAM is insufficient, prioritize reducing this parameter
- DPO training mode: Experimental feature, not recommended for first training
Training Order:
- Complete SoVITS training first
- Test SoVITS effect to ensure satisfactory timbre quality
- Then proceed with GPT training
- Test jointly using both models
1C-Inference

Speech synthesis interface, supporting both zero-shot and fine-tuned model modes.
Model Selection
Zero-shot inference: Select the “Infer directly without training” base model for both dropdowns
Fine-tuned model inference: Select the trained custom model (click “Refresh model path” button after training to update the list)
Inference WebUI
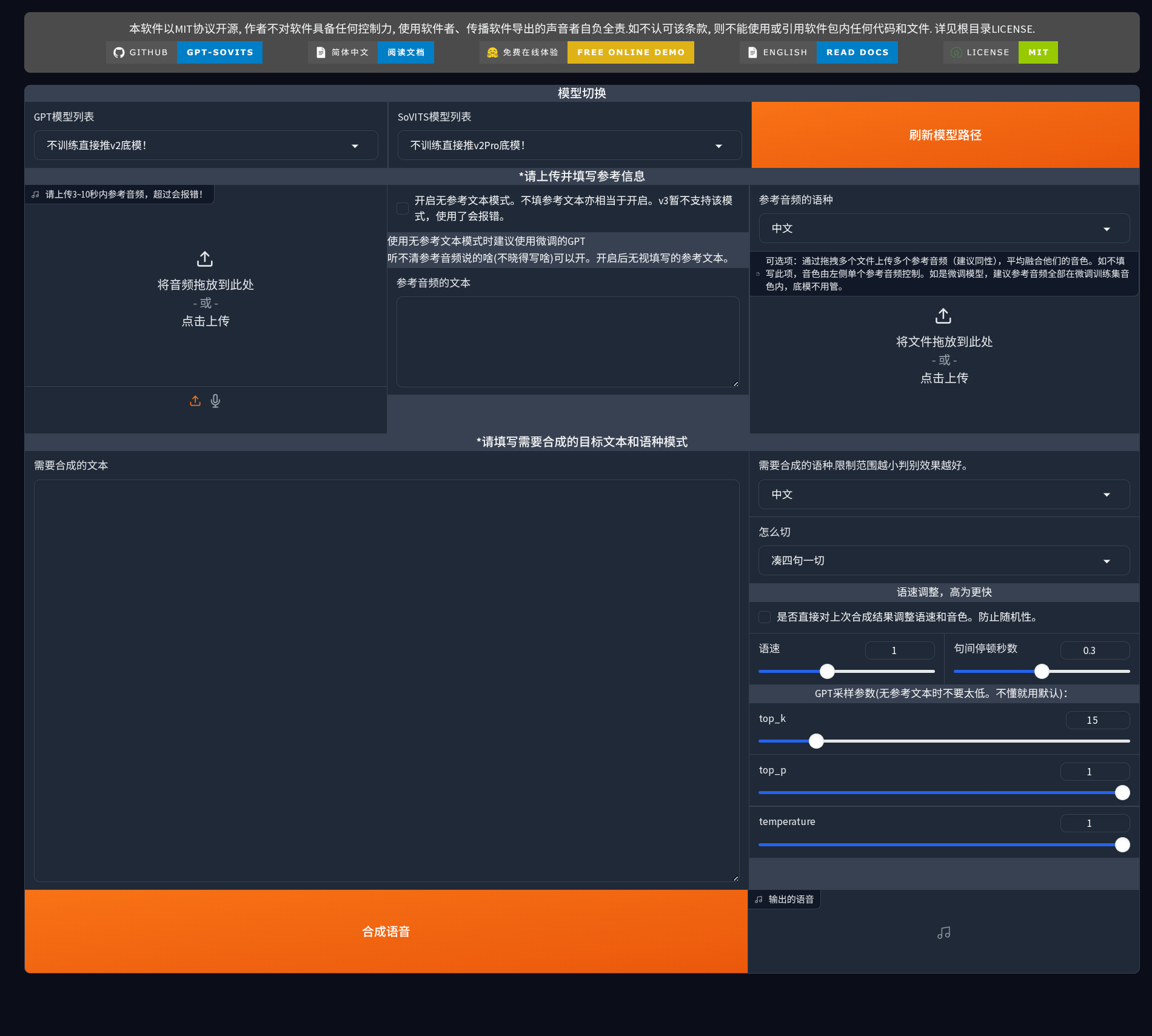
Click the “Close TTS Inference WebUI” button to launch an independent inference interface (usually at http://localhost:9872/).
Left: Reference Audio and Text
- Reference Audio: Upload 3-10 seconds of clear target timbre audio
- Supports drag and drop, click to upload, or direct recording
- Audio quality directly affects cloning effect
- Synthesized Text: Enter the text to be converted to speech
- Pay attention to punctuation (affects prosody and pauses)
- Long text will be automatically segmented
Right: Synthesis Parameters
- Language Settings:
- Reference audio language: Set the language of the reference audio
- Synthesis language: Set the language of the output speech
- Supports cross-lingual cloning (e.g., generating English speech with a Chinese timbre)
- Splitting Method (how to split):
- Default “Split every four sentences” suitable for most scenarios
- For short text, “Do not split” can be selected
- For long text, it is recommended to split by punctuation
- Speech Rate Adjustment: Default 1.0, range 1.0-1.5
- Keeping default is most natural
- Not recommended to exceed 1.3
- Pause between sentences: Default 0.3 seconds
- Normal conversation: 0.2-0.4 seconds
- Reading style: 0.4-0.6 seconds
GPT Sampling Parameters (Advanced):
- top_k (default 15): Controls sampling conservatism
- Lower (5-10): More stable and consistent
- Higher (20-50): More natural and diverse
- top_p (default 1): Nucleus sampling threshold, recommended to keep default or 0.8-0.95
- temperature (default 1): Controls randomness
- 0.6-0.9: More stable
- 1.1-1.3: More variation
- 1.0 is most balanced
After configuration, click the “Synthesize Speech” button. The generated audio will be displayed at the bottom of the interface and can be played and downloaded directly.
Complete Usage Workflow
Quick Experience (Zero-shot)
- Launch WebUI
- Go to “1C-Inference” tab
- Select default base model
- Upload 3-10 seconds of reference audio
- Enter synthesis text
- Click “Synthesize Speech”
Fine-tuning Training (High Quality)
Phase One: Data Preparation
- Prepare 3-10 minutes of high-quality audio in the target timbre
- Use “0a-Vocal Separation” to clean audio (if there is background music)
- Use “0b-Audio Splitting” to split audio
- Use “0c-Speech Recognition” to generate text annotations
- Use “0d-Proofread Annotations” to manually correct errors
Phase Two: Data Formatting
In “1A-Training Set Formatting Tool”:
- Execute “1Aa-Text Tokenization and Feature Extraction”
- Execute “1Ab-Audio Self-Supervised Feature Extraction”
- Execute “1Ac-Semantic Token Extraction”
Or directly use “One-Click Triple Action”
Phase Three: Model Training
In “1B-Fine-tuning Training”:
- Configure SoVITS training parameters, click “Start SoVITS Training”
- Wait for training to complete (monitor loss value changes)
- Configure GPT training parameters, click “Start GPT Training”
- Wait for training to complete
Phase Four: Inference Testing
- Go to “1C-Inference”
- Refresh and select the trained model
- Upload reference audio (can be shorter after fine-tuning)
- Enter test text
- Adjust parameters and generate speech
- Evaluate results, adjust parameters and regenerate if necessary
Optimization Suggestions
Inaccurate timbre:
- Increase training data volume (5-10 minutes)
- Ensure training data is clean and timbre consistent
- Adjust SoVITS training epochs
Unnatural prosody:
- Check accuracy of punctuation in text annotations
- Try different splitting methods
- Adjust GPT training epochs
Unclear audio quality:
- Improve original audio quality
- Check splitting parameters (avoid overly short segments)
- Reduce speech rate during synthesis
Practical Application Scenarios
Content Creation:
- Audiobook and podcast production
- Video dubbing and narration
- Game character voices
- Multilingual content localization
Assistive Technology:
- Personalized voice assistants
- Language learning tools
- Accessibility aids
Enterprise Applications:
- Virtual customer service systems
- Corporate training materials
- Brand voice uniformity
Summary
GPT-SoVITS brings professional-grade voice cloning technology to a wider user base, with its innovative two-stage architecture achieving a balance of high quality and low data requirements.
Getting Started Paths:
- Quick Test: Docker + Zero-shot Inference
- Professional Production: Manual Installation + Fine-tuning Training
The project is continuously updated. Visit the GitHub repository for the latest documentation and pre-trained models.